LLMs.txt is a plain text file placed at your domain root that tells AI crawlers - ChatGPT, Gemini, Claude, Perplexity, and others - which parts of your website they can access, summarize, or use to train models. Think of it as robots.txt for the AI era: a communication layer between your content and the systems increasingly responsible for how users discover and consume information.

What LLMs.txt Is and Where It Comes From
The robots.txt convention gave website owners a way to communicate crawl preferences to search engines. It was advisory, widely respected, and became a standard part of the technical SEO infrastructure.
Something analogous is now emerging for AI systems, and the decision about how to approach it is more commercially nuanced than robots.txt ever was.
LLMs.txt is a proposed standard for communicating to large language model crawlers how your content should be accessed, used, and restricted.
Unlike robots.txt, which primarily addresses whether content is crawled and indexed, LLMs.txt is designed to address a more complex question: whether content can be used for AI model training, for real-time inference in AI-generated answers, or not accessed at all.
The reason this matters commercially is that the economics of AI content consumption are different from the economics of search indexing. When Googlebot crawls and indexes your content, that indexing eventually drives traffic back to your site. When an AI model trains on your content or uses it to generate a summary response, the value transfer flows the other way: your content improves the model, and the model's answer may reduce the user's need to visit your site.
LLMs.txt is a plain text file placed at the root of a domain that communicates content access preferences to AI crawlers. The format was proposed by Jeremy Howard of fast.ai in mid-2024 and has been gaining adoption among publishers, news organizations, and content businesses that want to establish explicit preferences for how their content is used by AI systems.
The file convention draws on the established pattern of robots.txt but is designed to handle distinctions that robots.txt cannot make. A publisher might want to allow AI systems to use their content in real-time to generate accurate responses that cite the source, while blocking the same content from being incorporated into model training data where attribution is lost.
Robots.txt cannot make that distinction. LLMs.txt is designed to.
The key conceptual difference from robots.txt is that LLMs.txt addresses what AI systems do with content after they access it, not just whether they access it. Allowing a crawler to read a page for indexing is a different decision from allowing a crawler to use that page's content to train a model that will then generate answers without citing the original source. LLMs.txt provides the vocabulary to make those distinctions explicit.
As of 2026, LLMs.txt is not a universally adopted standard in the way robots.txt is. Compliance varies by AI company. Some major LLM operators honour it; others have their own separate opt-out mechanisms; others do not yet have a clear stance.
The file has more immediate practical value for publishers taking a proactive stance on record than as an enforceable technical control, though that balance is shifting as the legal and regulatory environment around AI training data matures.
The Connection to Generative Engine Optimization (GEO)
Generative Engine Optimization (GEO) is the emerging practice of optimizing content to appear in AI-generated answers - from ChatGPT to Google AI Overviews to Perplexity - rather than just ranking in traditional blue-link search results.
Where traditional SEO focuses on ranking signals (backlinks, on-page optimization, Core Web Vitals), GEO focuses on whether AI systems cite your content as a source when answering user questions in your domain.
LLMs.txt is a foundational element of GEO strategy for two reasons:
- It enables selective citation access. A brand that wants its educational content cited in AI answers can allow inference access to those pages while blocking training-data access to proprietary research. This selective openness makes GEO citation possible without surrendering all content to model training.
- It signals AI-friendly intent to crawlers. AI systems increasingly distinguish between publishers who have opted in to citation use and those who have blocked all access. Being explicitly accessible for inference (with appropriate restrictions) positions your content to appear in AI answer surfaces.
For Indian brands and businesses, GEO matters because Indian consumers are adopting AI search assistants rapidly - particularly for research-phase queries before purchase decisions. Being cited in AI responses to category questions ("what is the best ecommerce SEO agency in India?" or "how do I set up WhatsApp for business?") has significant commercial value that traditional organic rankings in isolation cannot capture.
How LLMs.txt Differs from robots.txt
| Dimension | robots.txt | llms.txt |
|---|---|---|
| Primary audience | Search engine crawlers (Googlebot, Bingbot, etc.) | AI training and inference crawlers (GPTBot, ClaudeBot, CCBot, Google-Extended, etc.) |
| Core function | Controls which pages are crawled and indexed | Controls which content can be accessed, summarized, or used for AI training |
| Enforcement mechanism | Widely respected by all major search engines; non-compliance risks de-indexing | Voluntary compliance; adoption varies by AI company; no universal standard yet |
| Legal standing | Widely recognized in webmaster practice; cited in legal proceedings | Emerging standard; legal weight is still being established |
| Specificity of control | Allow or disallow by path and crawler | Can differentiate between use for training vs. inference; can allow summarization while blocking training |
| Urgency in 2026 | Essential, already standard | Increasingly important as AI crawl volume grows and enforcement frameworks mature |
The enforcement gap is the most important practical caveat.
robots.txt is respected by search engines because violating it carries commercial consequences for those companies. Google's crawl infrastructure depends on site cooperation, and ignoring robots.txt directives at scale would damage the relationships that make web indexing possible.
The same enforcement dynamic does not yet exist as clearly for AI crawlers, though it is developing as lawsuits and regulatory pressure increase the cost of ignoring publisher preferences.
The practical implication is that LLMs.txt is most valuable as a clear, documented statement of your preferences, combined with the use of the AI-specific opt-out mechanisms that individual companies provide. Some of the major ones: Google provides an opt-out from Google-Extended (used for Gemini training) via robots.txt. OpenAI respects GPTBot disallow directives in robots.txt. Anthropic provides similar mechanisms.
LLMs.txt functions as the overarching policy document; robots.txt directives for specific AI crawlers provide the more immediately enforceable controls.
The Commercial Case for Taking This Seriously
The decision about AI content access is fundamentally a business decision, not just a technical one. The framing of "protect your content" or "block AI" is too simple. For most content businesses, the right answer is a differentiated access policy that optimizes across multiple competing interests.
The Traffic Displacement Reality
AI-generated answers are reducing click-through rates from search results for informational queries. When a user asks ChatGPT or uses Google's AI Overview and gets a complete answer synthesized from multiple sources, the likelihood of clicking through to any individual source decreases. If your content contributed to that answer, you generated value for the AI system without receiving the traffic that would previously have come from the equivalent search result.
The magnitude of this effect varies significantly by content type.
For content that answers factual questions or provides how-to guidance, AI summarization is a material traffic displacement risk.
For content that establishes credibility, showcases products, or requires the user to take an action (booking, purchasing, contacting), the displacement effect is smaller because the AI summary cannot replace the destination.
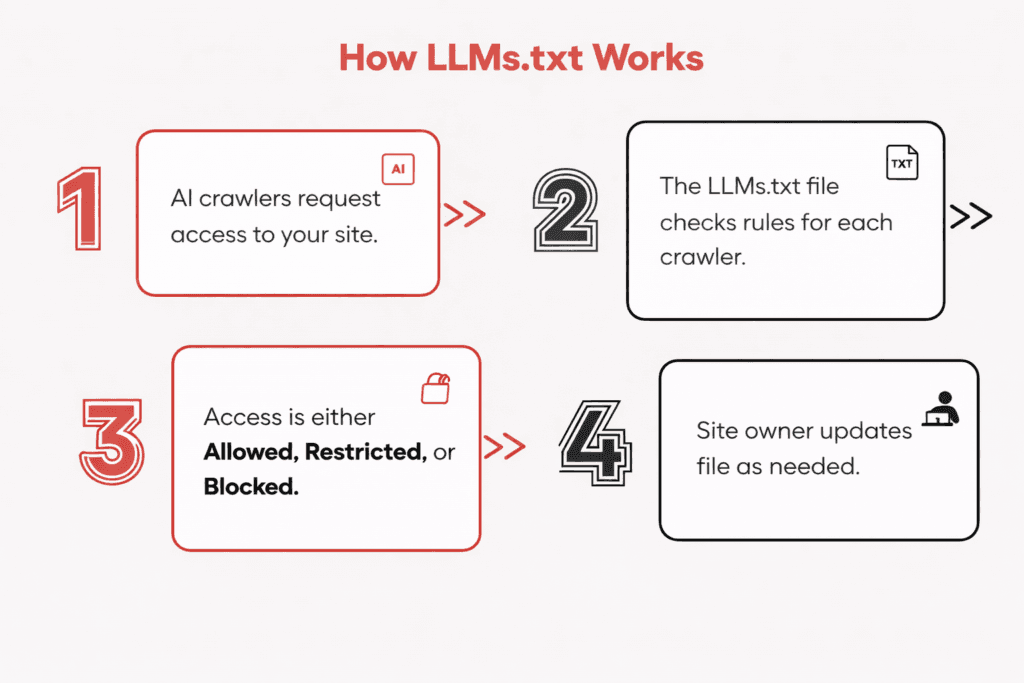
The Visibility Opportunity
The traffic displacement argument argues for restriction. The visibility argument argues for selective openness. AI systems that can access and cite your content are, in some contexts, driving qualified referrals and brand recognition.
Being cited as a source in an AI Overview or a ChatGPT response that a potential buyer sees during research has marketing value. The question is whether the visibility benefit outweighs the traffic cost for each category of content.
This is why the answer is rarely to block everything or allow everything. The commercially rational approach is a content-type-specific access policy.
The Training Data Question
There is a separate question embedded in the AI access discussion that most coverage conflates with the visibility question: whether your content should be used to train AI models.
This is distinct from whether AI systems can access your content to generate real-time answers.
A model that trains on your content is incorporating your intellectual work into its parameters, from which it will generate responses indefinitely, without attribution, compensation, or any ongoing relationship with your site.
Many publishers and content businesses have arrived at a position of: allow AI inference (real-time access for answer generation, with citation), decline AI training (incorporation into model parameters). LLMs.txt provides the vocabulary to express that distinction explicitly.
The Access Strategy Framework
The right LLMs.txt policy for your site depends on your content type, your business model, and your assessment of the traffic displacement versus visibility trade-off for each content category. The table below provides a starting framework.
| Content Type | Recommended Access Level | Rationale |
|---|---|---|
| Marketing blog, public guides, educational content | Open access (allow all) | Broad AI visibility supports brand awareness and discovery without material traffic cost |
| Product pages, pricing pages | Allow summarization; block training | Being cited in AI buying recommendations has commercial value; using your pricing data for training does not |
| Proprietary research, original data, paid reports | Block all AI access | This content is a commercial asset; AI training on it transfers value without compensation |
| Gated content behind authentication | Block all AI access | Content behind a paywall should not be accessible to crawlers of any kind |
| News and editorial content | Case-by-case; consider licensing approach | News organizations are pursuing licensing agreements with AI companies; blocking may be appropriate while negotiations are live |
| Technical documentation and help center content | Open for inference; consider blocking for training | Being cited in AI answers to support queries has value; contributing to model training indefinitely is a separate question |
The practical exercise is to audit your content library against these categories and make an explicit decision about each. This is not a set-and-forget decision. The AI landscape is changing quickly enough that a policy that makes sense in early 2026 may need revision by mid-2026 or early 2027 as enforcement mechanisms mature and as the traffic displacement effects become more quantifiable in your own analytics.
How to Create and Deploy LLMs.txt
The implementation is technically straightforward. The strategic decisions are the harder part. Technical SEO services India practitioners typically handle LLMs.txt deployment alongside robots.txt updates as part of a broader crawl governance review.
Here is the practical implementation process once you have made your access decisions.
File Structure and Syntax
LLMs.txt lives at the root of your domain as a plain text file (yourwebsite.com/llms.txt). The file uses a simple syntax similar to robots.txt: user-agent lines specify which crawlers the rule applies to, and allow or disallow lines specify which paths are accessible. A wildcard (*) applies the rule to all AI crawlers.
A basic example that allows all AI crawlers access to public blog content while blocking your proprietary research directory:
User-agent: *
Allow: /blog/
Allow: /guides/
Disallow: /research/
Disallow: /reports/
User-agent: GPTBot
Disallow: /
The file must be lowercase (llms.txt, not LLMs.txt or LLMS.txt), publicly accessible without authentication, and served with a text/plain content type. The specificity of your directives depends on how granular you want your access policy to be.
For sites using a CMS, the file can typically be uploaded directly to the root directory via FTP or file manager, or created as a static file served from the same location as your robots.txt.
Verify accessibility by navigating to yourwebsite.com/llms.txt directly in a browser before considering the implementation complete.
Known AI Crawler User Agents
As of 2026, the AI crawlers with documented user agents that site operators should be aware of include:
- GPTBot and ChatGPT-User (OpenAI)
- Google-Extended (Google, used for AI training and Gemini)
- ClaudeBot (Anthropic)
- CCBot (Common Crawl, used to build training datasets for multiple AI systems)
- PerplexityBot (Perplexity AI)
- Applebot-Extended (Apple, used for Apple Intelligence training)
The list is not exhaustive and will grow. Monitoring your server logs or a web application firewall for unrecognized crawler user agents is the most reliable way to stay current on which AI systems are accessing your content.
Cloudflare's bot analytics and Google Search Console crawl stats provide a reasonable starting point for this monitoring without requiring custom logging infrastructure.
Supplementing LLMs.txt With robots.txt Directives
Because LLMs.txt compliance is voluntary and variable, supplementing it with robots.txt disallow directives for the AI crawlers that respect robots.txt provides more immediately practical control.
Adding specific disallow blocks for GPTBot, Google-Extended, and CCBot in robots.txt implements your access preferences in a format those systems are already configured to respect.
The two files serve different purposes and should be maintained separately. robots.txt handles the crawlers that respect it. LLMs.txt serves as the documented policy statement for all AI systems, including those whose compliance is still developing.

The Honest Assessment: What LLMs.txt Can and Cannot Do
LLMs.txt is a declaration of intent, not an enforcement mechanism. Understanding the limits matters for setting realistic expectations about what implementing it actually achieves.
What It Does
It establishes a documented, public record of your content access preferences. This matters legally as the regulatory environment around AI training data develops: having an explicit LLMs.txt on record provides evidence of your stated preferences, which may be relevant in disputes about unauthorized content use.
It also signals to AI companies that take these standards seriously that your site has a considered access policy.
For AI crawlers that are actively implementing LLMs.txt support, the file directly controls access. This set is growing as the standard gains adoption and as AI companies respond to legal and regulatory pressure to respect publisher preferences.
What It Does Not Do
LLMs.txt does not retroactively affect training data. If an AI model was trained on your content before you published your LLMs.txt, the file has no effect on what that model already contains. It only affects future access by crawlers that respect it.
It does not prevent all unauthorized access. AI companies or data aggregators that choose not to respect LLMs.txt can still access your content through standard HTTP requests. The legal and reputational consequences of doing so are increasing, but the technical barrier is not significant.
It does not substitute for other content protection mechanisms. Gated content, authenticated pages, and content delivered via server-side rendering rather than static HTML all provide more robust technical access control than any text file directive.
The Emerging Publisher Response
News organizations and premium content publishers were among the first to engage seriously with AI content access as a business problem, because their revenue model is most directly affected by AI summarization. Users who get news summaries from AI assistants are less likely to click through to the original article, which reduces ad revenue and undermines subscription conversion.
The publisher's response has been multi-pronged:
- Some have negotiated licensing agreements directly with AI companies, establishing a paid access model analogous to wire service licensing.
- Others have implemented technical blocks on AI crawlers via robots.txt while pursuing licensing negotiations.
- Others have been more permissive, calculating that AI-driven brand visibility offsets the click displacement.
LLMs.txt provides a standardized format for expressing these access preferences across the range of approaches. A publisher pursuing licensing can use LLMs.txt to signal that their content is available for AI use on licensed terms while blocking unlicensed crawlers. A publisher taking a more open stance can document that position explicitly.
The pattern that is emerging among sophisticated content businesses is: block AI training data collection, allow AI inference with citation requirements where technically enforceable, monitor closely, and revisit every six months as the legal and technical landscape develops.
The Strategic Timeline: When to Act and What to Monitor
The urgency of implementing LLMs.txt depends on your content type and the degree to which AI summarization is already affecting your traffic.
For content businesses that have seen meaningful declines in organic click-through rates from informational queries over the past 12 to 18 months, the AI summarization effect is already affecting your numbers and the access policy decision is overdue.
For sites where AI-driven traffic displacement is not yet measurable, implementing LLMs.txt now still makes sense as a proactive measure. The legal and regulatory environment is moving toward requiring clearer data governance from AI companies, and having your preferences documented before those requirements are enforced positions you correctly.
The monitoring cadence should match the pace of change in the space:
- Review your LLMs.txt policy and the crawler landscape at least quarterly in 2026.
- Check your server logs for new AI crawler user agents and assess whether your current directives address them.
- Monitor your organic click-through rate trends in Google Search Console, segmented by query type, to detect signs of AI summarization affecting your informational content.
- Revisit the trade-off between openness and restriction as the licensing market for AI training data develops and as more AI companies formalize their compliance posture on LLMs.txt directives.
For large sites managing thousands of URLs, an enterprise SEO audit is the most reliable way to identify which content categories are most exposed to AI summarization displacement and should therefore be prioritized in your access policy review.
Frequently Asked Questions
What is GEO and why do I need to think about it alongside LLMs.txt?
Generative Engine Optimization (GEO) is the practice of optimizing your content to appear in AI-generated answers - from ChatGPT, Google AI Overviews, Perplexity, and similar systems - rather than just traditional search rankings. LLMs.txt and GEO are complementary: LLMs.txt controls which AI systems can access your content, while GEO optimization improves the likelihood that AI systems with access will actually cite your content in their responses. Both are now part of a complete search visibility strategy in 2026.
Should I block all AI crawlers with my LLMs.txt file?
Blocking all AI access makes sense for paywalled content, proprietary research, and pricing data that you do not want used for model training. For publicly available educational and marketing content, blanket blocking typically reduces your GEO visibility without a proportional benefit. The recommended approach is granular: allow inference (real-time AI citation) for public content, block training-data collection for commercially sensitive content. This gives you AI citation benefits while protecting content that has standalone commercial value.
How do I know if AI crawlers are already accessing my site?
Check your server access logs or Cloudflare bot analytics for user agents including GPTBot, ClaudeBot, Google-Extended, CCBot, and PerplexityBot. Google Search Console's Crawl Stats report shows crawl activity by user agent type. If you see significant AI crawler volume, your content is already being accessed - whether that access is desirable depends on your content strategy, which is exactly what LLMs.txt helps you communicate.
Is LLMs.txt relevant for small businesses and local businesses in India?
For most local and small businesses in India, LLMs.txt is a low-priority implementation - the content cannibalization risk from AI summarization is lower for service businesses with location-specific content and action-oriented pages (contact, booking, pricing) that AI cannot replace. Where LLMs.txt becomes relevant for small Indian businesses is if they publish significant educational or guide content that answers general questions in their category, because that content type is most susceptible to zero-click AI answers. If you are publishing blog content to drive organic traffic, implementing a basic LLMs.txt that allows inference while blocking training is a prudent baseline.
Conclusion
LLMs.txt is where robots.txt was in 2001: an emerging standard with uneven adoption and uncertain enforcement, but clear directional importance. The brands that document their AI content access preferences now will have those preferences on record when enforcement mechanisms mature and when the legal environment crystallizes around AI training data rights.
More immediately, LLMs.txt is a foundational element of GEO - the practice of optimizing your content for citation in AI-generated answers, which is becoming a material channel for brand discovery in 2026. Allowing AI inference access to your public educational content while protecting proprietary data is the starting position most brands should adopt.
The implementation takes under an hour. The strategic decision about which content categories to allow or restrict requires more thought. But both are worth doing now, before the policy defaults are effectively set for you by others.
If you want help thinking through the right AI access policy for your site and implementing LLMs.txt correctly alongside your broader technical SEO infrastructure, book a free consultation → We'll review your content mix and recommend a GEO and LLMs.txt strategy that matches your business model.

Aditya Kathotia
Founder & CEO
CEO of Nico Digital and founder of Digital Polo, Aditya Kathotia is a trailblazer in digital marketing. He's powered 500+ brands through transformative strategies, enabling clients worldwide to grow revenue exponentially. Aditya's work has been featured on Entrepreneur, Economic Times, Hubspot, Business.com, Clutch, and more. Join Aditya Kathotia's orbit on LinkedIn to gain exclusive access to his treasure trove of niche-specific marketing secrets and insights.